{kind=link}
Присоединяйтесь к событию, которым доверяют лидеры предприятия в течение почти двух десятилетий. VB Transform объединяет людей, строящих реальную стратегию ИИ предприятия. Узнать больше
Китайский AI Startup Minimax, возможно, наиболее известный на Западе за свою реалистичную видео-модель AI Hailuo, выпустила свою новейшую модель большого языка, Minimax-M1-и в отличных новостях для предприятий и разработчиков, она полностью открыта по лицензии Apache 2.0, а это означает, что предприятия могут принять его и использовать его для коммерческих приложений и изменять его в симпатию без ограничения или оплаты.
M1-это предложение с открытым весом, которое устанавливает новые стандарты в рассуждениях о длинном контексте, использовании агента и эффективной производительности вычислительной работы. Он доступен сегодня в сообществе сообщества, обнимающего обнимание Code Code Code, и конкурирующее сообщество Microsoft Community Github, первое выпуск того, что компания назвала «Minimaxweek» из своего социального аккаунта на X — с ожидаемыми дальнейшими объявлениями о продукте.
Minimax-M1 отличается контекстным окном в 1 миллион входных токенов и до 80 000 токенов в выводе, позиционируя его как одну из самых экспансивных моделей, доступных для задач рассуждения с длинным контекстом.
«Контекстное окно» в моделях крупных языков (LLMS) относится к максимальному количеству токенов, которые модель может обрабатывать за один раз, включая как вход, так и вывод. Токены являются основными единицами текста, которые могут включать в себя целые слова, части слов, знаки препинания или символы кода. Эти токены преобразуются в численные векторы, которые модель использует для представления и манипулирования значением с помощью своих параметров (веса и смещения). По сути, это родной язык LLM.
Для сравнения, GPT-4O OpenAI имеет контекстное окно составляет всего 128 000 токенов-достаточно, чтобы обмениваться информацией о романе между пользователем и моделью в одном взаимодействии вперед и назад. На 1 миллион токена, Minimax-M1 может обменять небольшой коллекция или информация о ценности книг. Google Gemini 2.5 Pro предлагает верхний предел контекста токена в 1 млн. 1 млн., Со вкладом сообщается о 2 миллионах окна.
Но у M1 есть еще один трюк в рукаве: он был обучен с использованием обучения подкреплению по инновационной, изобретательной, высокоэффективной технике. Модель обучается с использованием архитектуры гибридной смеси экспертов (MOE) с механизмом внимания молнии, предназначенным для снижения затрат на вывод.
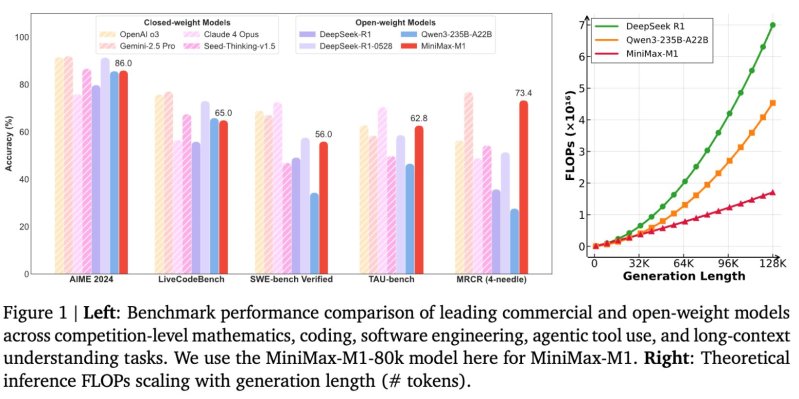
Согласно техническому отчету, Minimax-M1 потребляет только 25% от операций с плавающей запятой (провалов), требуемых DeepSeek R1 с длиной поколения 100 000 токенов.
Архитектура и варианты
Модель поставляется в двух вариантах-Minimax-M1-40K и Minimax-M1-80K-обрабатывая их «бюджеты мышления» или длину выхода.
Архитектура построена на более раннем фонде компании Minimax-Text-01 и включает в себя 456 миллиардов параметров, с 45,9 млрд. Активированных на токен.
Выдающейся особенностью релиза является стоимость обучения модели. Minimax сообщает, что модель M1 была обучена с использованием крупномасштабного обучения подкреплению (RL) с эффективностью, редко наблюдаемой в этом домене, общая стоимость 534 700 долларов США.
Эта эффективность приписывается пользовательскому алгоритму RL под названием CISPO, который зажигает важность выборки веса, а не обновления токенов, а также гибридную конструкцию внимания, которая помогает оптимизировать масштабирование.
Это удивительно «дешевая» сумма для Frontier LLM, так как Deepseek обучил свою популярную модель рассуждений R1 по сообщению о стоимости 5-6 миллионов долларов, в то время как стоимость обучения GPT-4 Openais-более чем двухлетняя модель, которая сейчас превысила 100 миллионов долларов. Эта стоимость поступает как цены на графическую обработку (графические графические процессоры), массивно параллельное оборудование для вычислений, в основном производимые такими компаниями, как Nvidia, которое может стоить 20 000–30 000 долл. США или более на модуль, а также от энергии, необходимой для постоянного запуска этих чипов в крупномасштабных центрах обработки данных.
Эталонная производительность
Minimax-M1 был оценен в серии установленных критериев, которые тестируют расширенные мышления, разработку программного обеспечения и возможности использования инструментов.

На AIME 2024, эталон конкурса по математике, модель M1-80K оценивает точность 86,0%. Это также обеспечивает сильную производительность в кодировании и задачах с длинным контекстом, достигая:
- 65,0% на LiveCodebench
- 56,0% на проверке SWE-Bench
- 62,8% на Тау-Бенке
- 73,4% на Openai MRCR (версия 4-needle)

Эти результаты ставят Minimax-M1 перед другими конкурентами с открытым весом, такими как DeedSeek-R1 и QWEN3-235B-A22B, по нескольким сложным задачам.
В то время как модели с закрытым весом, такие как OPE O3 и Gemini 2.5 Pro, по-прежнему превышают некоторые тесты, Minimax-M1 значительно сужает разрыв в производительности, оставаясь свободно доступным по лицензии Apache-2.0.
Варианты развертывания и инструменты разработчика
Для развертывания Minimax рекомендует VLLM в качестве бэкэнда порции, ссылаясь на его оптимизацию для больших рабочих нагрузок, эффективности памяти и обработки запросов на пакет. Компания также предоставляет варианты развертывания с использованием библиотеки Transformers.
Minimax-M1 включает в себя способности вызова структурированной функции и упаковывается с API чат-бота, включающий онлайн-поиск, генерацию видео и изображений, синтез речи и инструменты голосового клонирования. Эти функции направлены на поддержку более широкого агентского поведения в реальных приложениях.
Последствия для технических лиц, принимающих решения и покупателей предприятий
Открытый доступ Minimax-M1, возможности длительного контекста и вычисляйте эффективность.
Для инженерных лидеров, ответственных за полный жизненный цикл LLMS, такой как оптимизация производительности модели и развертывание в условиях жестких сроков, Minimax-M1 предлагает более низкий профиль эксплуатационной стоимости при поддержке передовых задач. Его длинное контекстное окно может значительно сократить усилия по предварительной обработке для предприятий или данных, которые охватывают десятки или сотни тысяч токенов.
Для тех, кто управляет оркестровками ИИ, способность тонкой настройки и развертывания Minimax-M1 с использованием установленных инструментов, таких как VLLM или Transformers, поддерживает более легкую интеграцию в существующую инфраструктуру. Архитектура гибридного активации может помочь упростить стратегии масштабирования, а конкурентная производительность модели на многоэтапных рассуждениях и контрольных показателях разработки программного обеспечения предлагает базу с высокой способностью для внутренних апотиров или агентских систем.
С точки зрения платформы данных, команды, ответственные за поддержание эффективной, масштабируемой инфраструктуры, могут извлечь выгоду из поддержки M1 для структурированных вызовов функций и ее совместимости с автоматическими трубопроводами. Его природа с открытым исходным кодом позволяет командам адаптировать производительность к своему стеку без блокировки поставщиков.
Ведущие безопасности также могут найти ценность при оценке потенциала M1 для безопасного, локального развертывания модели с высокой способностью, которая не полагается на передачу конфиденциальных данных в сторонние конечные точки.
Взятые вместе, Minimax-M1 представляет гибкий вариант для организаций, стремящихся экспериментировать с расширенными возможностями ИИ или расширенными возможностями при управлении затратами, оставаясь в рамках эксплуатационных пределов и избегая запатентованных ограничений.
Выпуск сигнализирует о постоянном фокусе Minimax на практических, масштабируемых моделях ИИ. Объединяя открытый доступ с расширенной архитектурой и вычислительностью эффективности, Minimax-M1 может служить основой для разработчиков, создающих приложения следующего поколения, которые требуют как глубины рассуждений, так и понимания входного ввода.
Мы будем отслеживать другие релизы Minimax в течение недели. Следите за обновлениями!
Источник